SBD Without Punctuation
Project Blog
Abstract
In this project, we will be focusing on sentence boundary detection (sbd) without punctuation marks. We will be researching current solutions from the Natural Language Processor, (NLP) splitta in order to provide us with results. Using the information gathered from conducting multiple tests, we will conclude why sbd is not accurate and form a solution to detect sentence segmentation without punctuation marks.
Syntactic Parsing
Parsing is the process of analyzing a string of symbols. Syntactic parsing is the task of recognizing a sentence and assigning a syntactic structure to it. However, structural ambiguity occurs when the grammar can assign more than one parse to a sentence. For example, if a sentence such as “One morning I shot an elephant in my pajamas. How he got into my pajamas I don’t know.” Once parsed, these collection of words would be difficult to analyze due to its ambiguous nature. Simple sentences such as “Good morning, how are you?” are easy for NPL to process because there is no ambiguity and has a straight forward structure. [https://web.stanford.edu]
Part of Speech Tagging (POS)
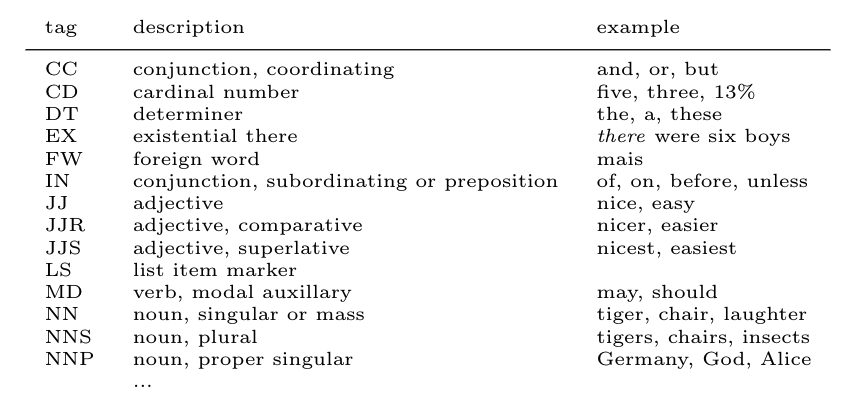
A big reason why NLP today has been successful is because of Part of Speech (POS) tagging. It helps programs capture the structure of the sentences and sometimes provides appropriate meanings. The part of speech is split into eight parts, which are nouns, pronouns, adjectives, verbs, adverbs, prepositions, conjunctions and interjections. Based on the current, previous, and next words, the software decides the which part of speech to tag the word with. The most popular tag set is Penn Treebank tagset:
What Started NLP?
The Georgetown experiment in 1954 introduced a fully automated machine that translated more than sixty Russian sentences to English. Researchers began to believe that machine translation would be a solved problem after five years. However, took on a much slower pace, as researchers failed to reach expectations. It was not until 1980 when progression in NLP had picked up again. The introduction of machine learning algorithms for language processing has sparked the interest of researchers. Avram Chomsky (famous for the contributions in linguistics) was a major contributor to the advancement in NLP.
How Google uses NLP today!
A portion of Googles current success can be in large part to NLP. Google Now uses NLP for syntax, part of speech tagging and parsing in 60+ languages. Semantics for Google Search recognizes entities in text to figure out the best search results for the user. Knowledge extraction to learn relations between entities, recognize events, match entities between queries and documents. All of this cannot be done in a couple of years. To build a company like Google with the software and technology that have developed takes thousands of workers with more than 5 years of craft.
My thoughts on SBD for NLP
After completing half of my project on sbd without punctuation. I have come to the realization that it will not be possible to have one system that works for every language. No matter how advanced AI develops, there is no possible way to detect sentence segmentation error free. This is in large part to humans not perfecting punctuation in languages. Although, it might be easy for a human to read and decide where a sentence ends and begins. It’s not for a NLP because of the multitude of exceptions and non-exceptions.
Natural Language Processing (NLP) for Arabic
Nearly 500 million people worldwide speak Arabic. The language of Arabic holds deep cultural, religious, and political significance. It is the fifth most spoken language in the world, the official language in 22 countries and is one of the six official United Nation languages. However, Arabic has received comparatively little attention in modern computational linguistics. It can be due to a number of reasons such as its complex tokenization. I believe once machine translation progresses, Semitic languages like Arabic will get more attention.
Natural Language Processing (NLP)
NLP is a branch of Artificial Intelligence (AI). It’s ability of a computer program to understand the human spoken language. Humans speak about 2,000 languages, each language also having their own set of rules.
Why is NLP Important?
In short, NLP helps with speech or text analytics. Some examples are text mining, machine translation, and automated question answering. It open doors to new possibilities of AI development, which can lead to efficient programs.
Some NLP Tools:
These programs include various languages
splitta(used for this project)
SBD for the Arabic language
Sbd for Arabic uses the following set of general rules:
• A period ending a sentence
• Based on the last word of the current sentence and the first word of the next sentence
There is no natural processing language tool for Arabic that can give us data for the error rates. I assume the error rate is higher than English because of the usage of punctuation in Arabic is peculiar. Also more research has been done for the English language.
SBD for the English language
Sbd for English uses the following set of general rules:
• A period ending a sentence
• The following token after a period is capitalized
• Multiple abbreviations not ending a sentence
These three strategies work 95% of the time. After including more rules like elephant does, sbd works 99.73%. That is very close to perfect, but not quite there yet. How can we make the error rate 0? Well the problem comes from ambiguous periods that stem from abbreviations, ellipses, and decimal points. There has been rules to combat this but never perfect.
Some Problem with SBD
1. One major flaw is detecting the end of a sentence without punctuation, which is what my project research is about.
2. Due to low error rates, sbd is a problem some consider to be solved. However, these small errors still lead to misguided data and analytics.
3. Most tokenizers are rule-based on each specific language. Such as English has its own set of rules that cannot be used for Italian. This makes it difficult to adapt to new languages. I believe if natural language processing tools continue with rules based segmentation then it will always be hard to adapt to new languages.